Flux training
Overview
Flux is a family of generative image models created by Black Forest Labs making use of some of the latest AI advancement such as diffusion, transformer (MMDiT), Flow-matching and a large T5 text encoder.
The large text encoder allows the text2img model to better align the image with the given prompt and create complex images with a single prompt.
The model base resolution is 1024x1024 however unlike previous models, was trained on a variety of aspect ratios its neural-network architecture is able to better cope with different aspect ratios both in training and inference.
Flux1.dev requires commercial licensing which is provided to Astria customers.


Training presets
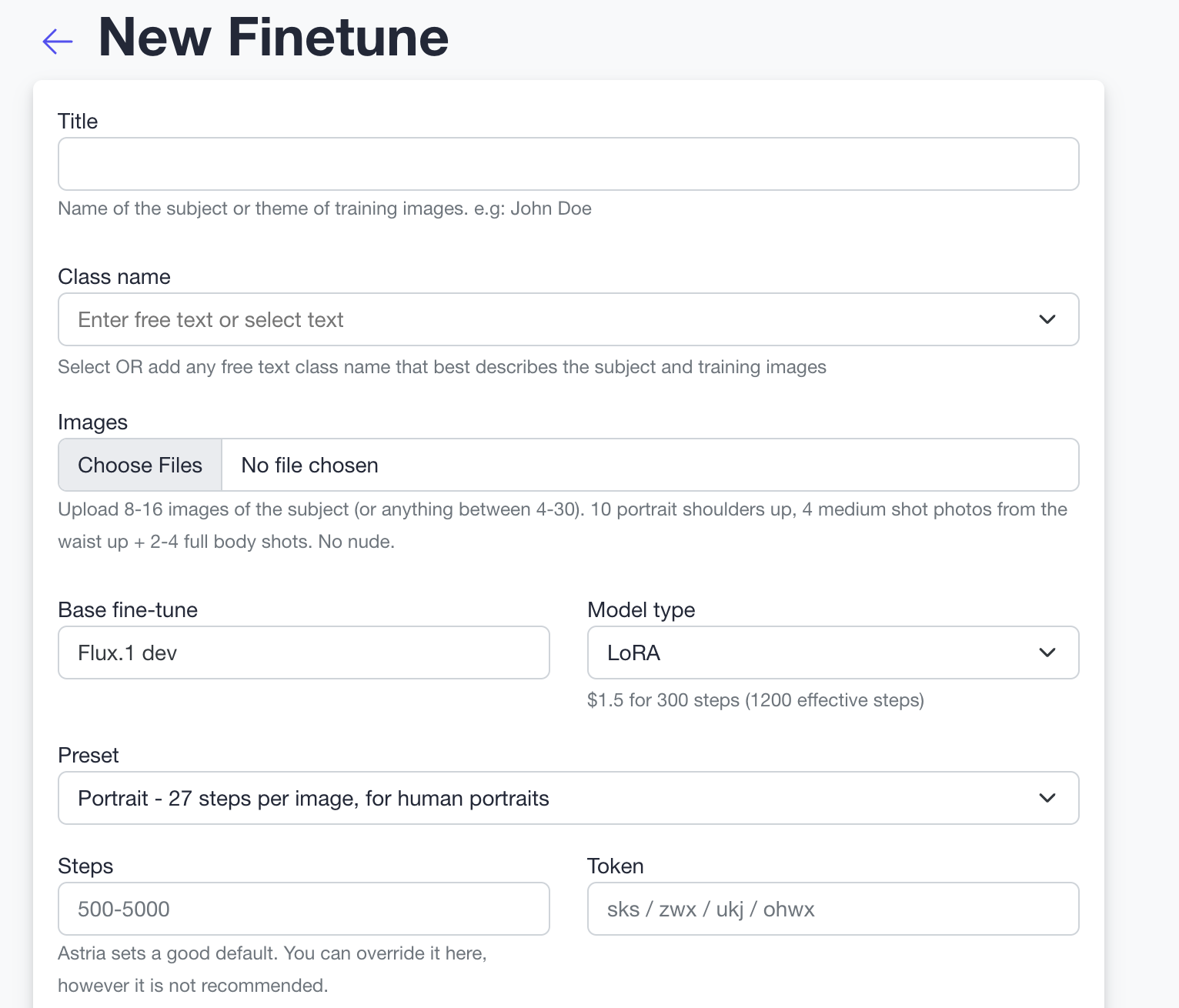
Astria uses training presets to evolve its training strategies and provide better results while also providing a stable API for its customers.
Our current recommendation is to use the portrait preset for training Flux models.
- Focus - API
flux-lora-focus- Focus preset automatically balances different types of training, allowing it to focus on faces, products as well as styles. - Portrait - API
flux-lora-portrait- This preset is generally recommended for any kind of training including non portraits, except forstyletraining. With the latestportraitwe now use more precise hyper-parameters for training, improved pre-processing, better handling of blurred/low-res images, face-cropping and focusing on learning face features, less overfitting to clothing and background. You will get more diverse images with better prompt alignment while better preserving identity and face. For this preset we default to 27 steps per image for training, with minimum steps of 300. You may override the number of steps depending on price and quality requirements. - Fast API
flux-lora-fast- Legacy preset. Provides an alternative for the high preset, with faster training and lower cost. Similarly to theportraitpreset, it uses 27 steps per image for training, with minimum steps of 300. - High API
null- High steps, low-learning rate. Should be used forstyletraining or training sets with 20+ images. With the high preset, we default to 100 steps per image for training, with minimum steps of 300. You may override the number of steps depending on price and quality requirements.
Training tips
Default token for SDXL should be ohwx and will be set automatically if none is specified
- As with other models, a good training set is critical to getting great results. See AI photoshoot guide
- Astria currently defaults to 100 steps per image for training a Flux lora for the high preset, and 27 steps per image for the fast preset. Fast preset is recommended when training on people or headshots.
- You may opt to override the number of training steps in order to reduce costs and processing time. Reducing the steps can produce good results when the target inference images are similar to the input training images (like headshots). Example lower steps could be 600, 1000 or 1200 (roughly 50-70 * number of training images )
Inference tips
- Dense prompts - Flux works best when the prompt is descriptive and detailed, but as in most models, be concise. Overdoing the description can create conflicts in the inference.
- *No negatives - Flux doesn’t work with negatives, instead we suggest using positive prompts. For example, instead of writing ‘cartoon’ in the negative, write ‘realistic settings and characters’ in the prompt.
- No weighted prompts - using weights or parentheses () to emphasis certain parts of a prompt doesn’t work with Flux. Instead, make sure the important parts at the beginning of the prompt.
- Adding text in the image - One of the advantages of Flux is the ability to add text to an image. There are a few ways to do that, like “ohwx man holding a sign with the words ‘Hello’“.
- Looking for prompt ideas? Try the Themes feature. Themes uses Claude GPT to help write prompts for the specific model. You can add a theme and write any topic on your mind, and themes will produce 10 prompts on it.
API usage
See here for API usage